My Ceph Cluster runs now! And it is amizingly powerful :-) Updates for Ceph Reef. Quincy is not yet the latest release anymore, I reinstalled my cluster with Reef (now…
Pushing the Rectangle Through the Round – Develop With RIOT OS on Windows – Doing The Impossible

Work in progress As many of you, I also have Windows 10 natively on my Notebook and don't want to switch to Linux, every time, I do some development that…
How To Open Your Zipper – Use Fuse To Browse Archives
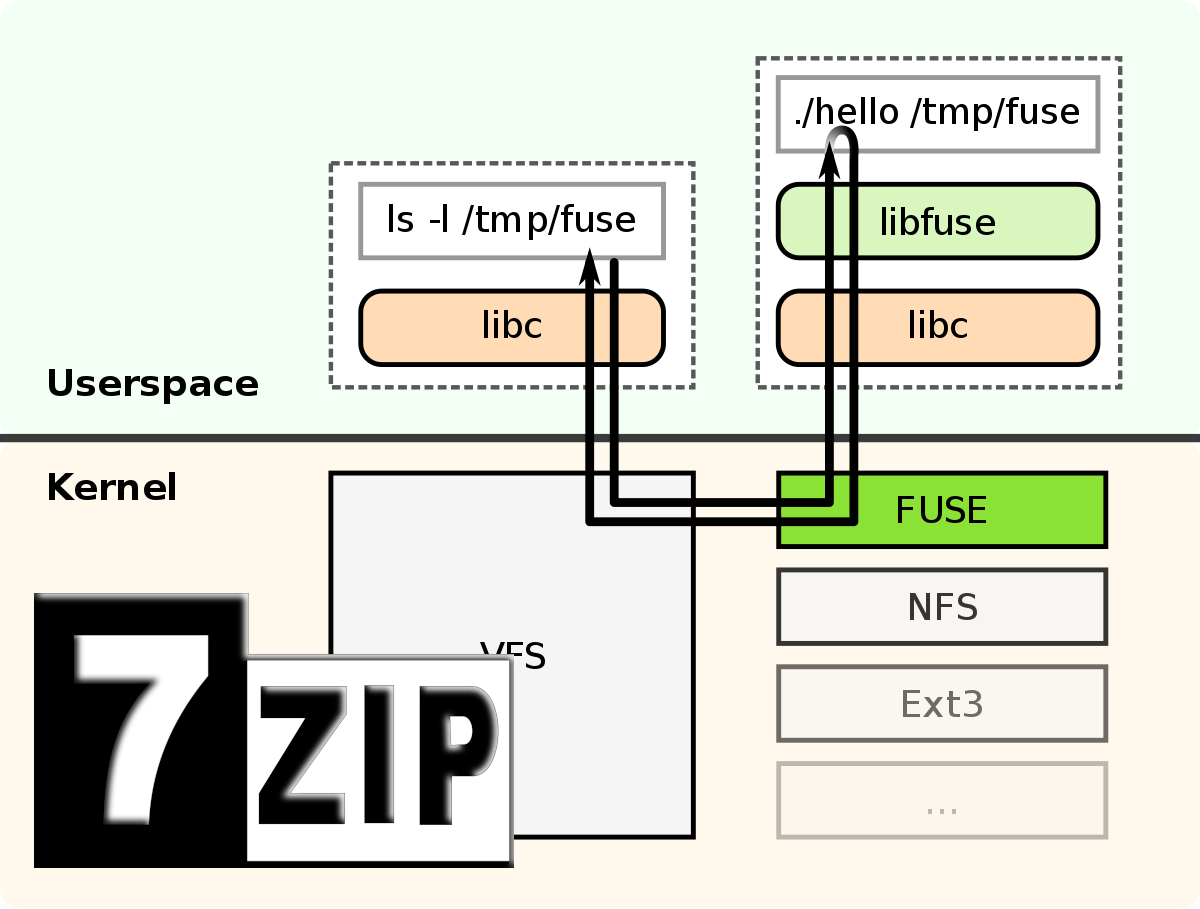
Since I did many Backups of important folder in former times using 7z (one snapshot had 14 GB), I was searching for a way to access it more easily. For…
Windows (was) just a pain
Since I use Linux at home and love to develop embedded, backend and (web)-fronteds within a real operating system, I sometimes get crazy at work, when I just search for…
Integrating wmBus devices into iobroker

Since I've replaced ioBroker with Home Assistant, I also wrote an article about integrating M-Bus devices via MQTT with HASS. Another post, doing the same with wmBus can be found…
Sorting Your Digital Mess – How to Easily Set-Up a Private Search Engine

Motivation In my vacations, I kicked-off some new projects. One of it is an ARM64 based SBC with integrated SATA mostly like the Odroid-HC1/2. The main difference is the ARM…
Installing BigBlueButton on Your Dedicated Server
Introduction After struggling with a dedicated server from Strato Webhosting, running ubuntu 18.04 and playing around with schroot to get some ubuntu 16.04 environment, I gave up with this solution.…
School’s out – How to Tame Your Children
Introduction - Historic Reasons for this Post Here in Germany, executive decided to lock all public life down to a minimum (only system relevant shops are allowed to be opened…
How To Debug Hardware-Faults on Your Dedicated Server
While installing some stuff on a dedicated server at Strato, I encountered a problem with the server two times. While having no clue what happened during the first time, I…
Merging the Contents of Two InfluxDBs
Eveer had the problem that data runs into two different influx databases and you want to merge the data into a single one? You wonder, why this can happen? Then…