My Ceph Cluster runs now! And it is amizingly powerful :-) Updates for Ceph Reef. Quincy is not yet the latest release anymore, I reinstalled my cluster with Reef (now…
How To Open Your Zipper – Use Fuse To Browse Archives
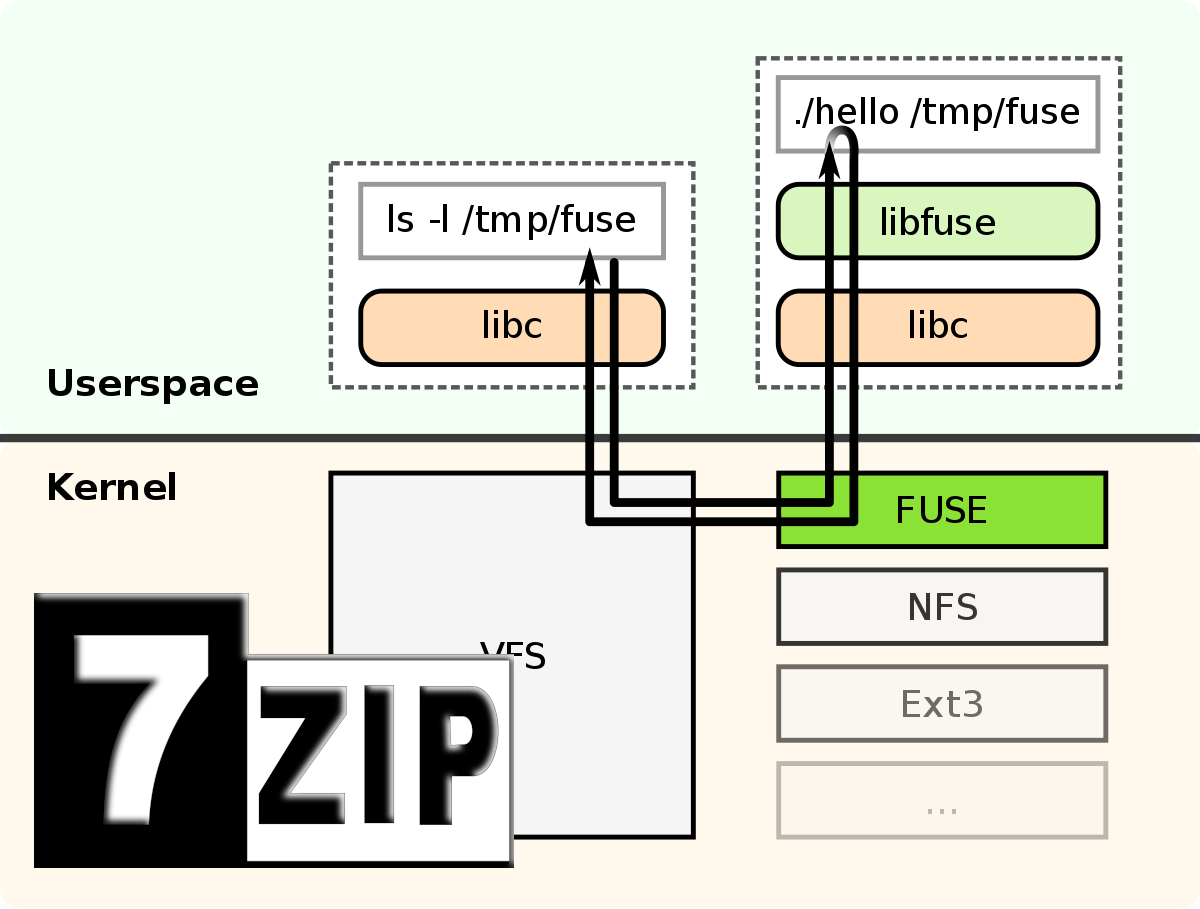
Since I did many Backups of important folder in former times using 7z (one snapshot had 14 GB), I was searching for a way to access it more easily. For…
Compile Ceph (master) on ARM (32-Bit)
I gave up on getting Ceph run on ARM 32 bit. It was a huge effort to fix the types, that diverge when switching from 64 to 32 bit. The…
How to Build A Private Storage Cluster (with Ceph)
Finally, I did not succeed in getting Ceph running on a 32 bit ARM. There have been to many issues in the code (especially incompatible datatypes) and issues with GCC…
Sorting Your Digital Mess – How to Easily Set-Up a Private Search Engine

Motivation In my vacations, I kicked-off some new projects. One of it is an ARM64 based SBC with integrated SATA mostly like the Odroid-HC1/2. The main difference is the ARM…