OK Guys, this could turn out to be a very long post since it will condense the work I've done over the past year in my basement. Maybe you will…
Mole’s Underground Heating System Can Not Be Over-Engineered 😋 (work in progress)
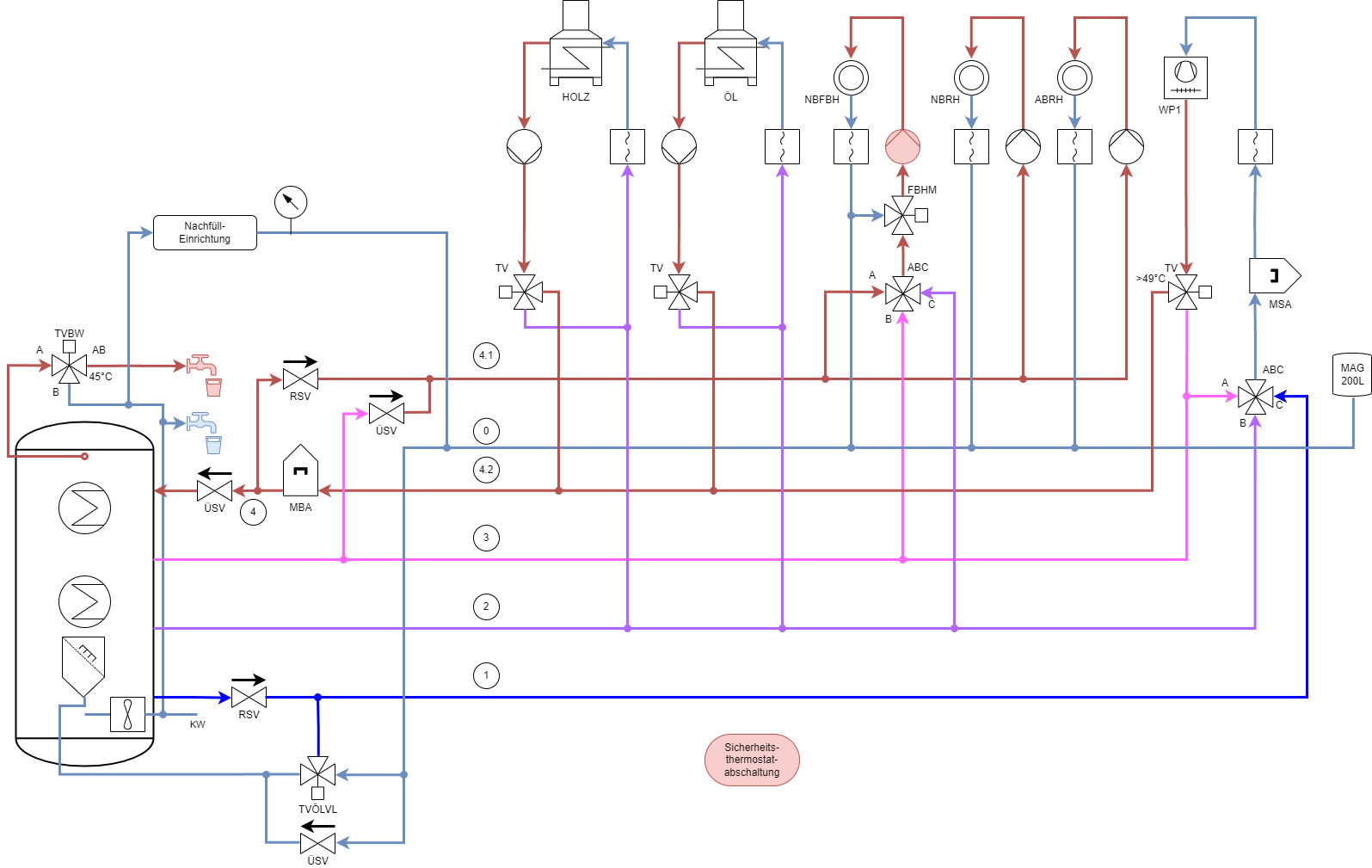
OK Guys, this could turn out to be a very long post since it will condense the work I've done over the past year in my basement. Maybe you will…

After migrating from iobroker to Home Assistant, I lost the level of my oil tank in my smart home, being forced to have a look into the smartphone app. That…

Introduction First of all, why would you do this? Many people own an appartment and want to measure the heat, water, electricity flow to the people living there. Others just…
After some discussion on the home assistant community forum about ESPhome and the M-Bus and the M-Bus in general, I decided to write a little post about the baiscs of…

I just thought about implemententing a small ESPhome based ultrasound water level module, when I realized, that I have none of my modules left. Maybe I gave the last one…

A few days ago, I received an IEC 62196 to Schuko (German Plug) adapter, to be able to draw 230V from a wall-box or public charger. I'll replace the Schuko…

Everybody playing around with hardware that has a serial port and is not located close to the desk will sooner or later run into the problem, that the wire simply…

Work in progress As many of you, I also have Windows 10 natively on my Notebook and don't want to switch to Linux, every time, I do some development that…
Have you ever been interested in the current EEX or more correctly the EPEX SPOT prices? If so, you quite certainly stumbled over the EPEX SPOT Home or the Energy…
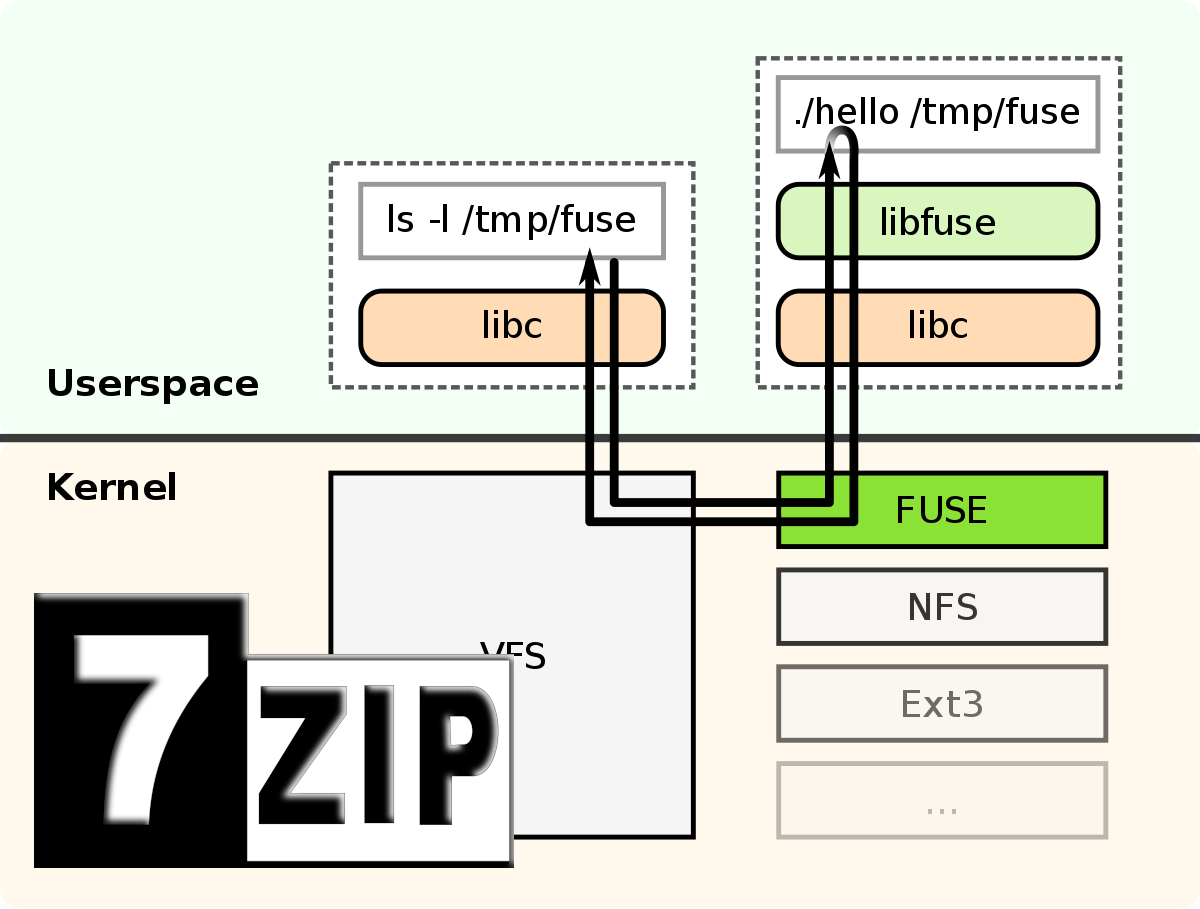
Since I did many Backups of important folder in former times using 7z (one snapshot had 14 GB), I was searching for a way to access it more easily. For…