My Ceph Cluster runs now! And it is amizingly powerful :-) Updates for Ceph Reef. Quincy is not yet the latest release anymore, I reinstalled my cluster with Reef (now…
Intensive Underground Metering – An RJ45 Breakout for Connecting Your Meters Through Ethernet Cabling

Again, I quickly developed a gadget to ease my life as a data collecting mole. ModBus adapters mostly have three drawbacks. Firstly, they have open wires, secondly, if you route…
Reverse Engineering the Buderus KM271 – And Making It WiFi-Flying on ESPhome and Home Assistant

If you bought one of my modules recently, it is also worth looking at the how-to project page for this module :-) Find a video how to assemble the board…
Crying on Open Waters – A Piece of HW for AhoyDTU and Reading the Hoymiles Inverters

It's quite some time ago, I wrote my last blog post. But I had a lot to do and there have been quite action, creating some material for new posts.…
In The Heat Of The Night – 1-Wire Temperature Sensor Directly Immersed

As always, I want to first quickly explain, what brought me to that project... If you look around in different stores and on aliexpress, you can find a ton of…
Doing the Undone – Decoding SML or Hacking the Tibber Raw Data

The Problem I Encountered... Just after installing the Pulse IR and the Tibber Bridge, I was quite a bit frustrated about the continuity of the Tibber data. This was not…
Code Red on Fire – Or Heat-Metering with Node-Red
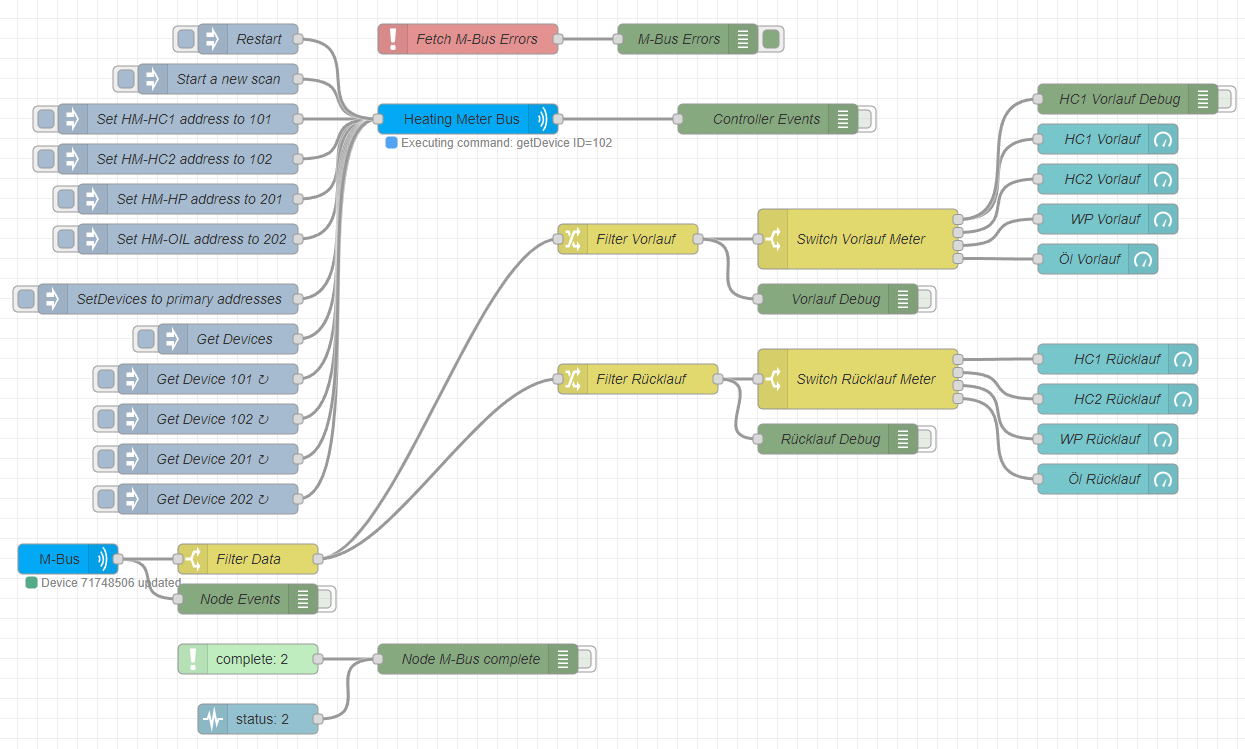
OK, guys, as you may have noticed when reading my post about my new heating system, I have three heat meters installed that have M-Bus connectivity. I also wrote some…
Smart Home Controlled Joy-IT Lab Power Supply

OK, you'll definitely believe, moles are crazy. You would ask, for what do you need a laboratory power supply that is controlled by your smart home (Home Assistant)? It's easy,…
MBus application layer
Introduction Previously on this series, a payload was obtained from a meter over the EN13757 protocol. Chapter 6.3, in a nutshell, means a variable-sized array of data blocks. Each block…
Reading a meter speaking MBus
Good day dudes and dudettes! I'm into software system architecture at least as much as I'm into coding. Otherwise, I could go on forever and a day about myself but…